
Unlock GPU Cloud in 5 Minutes. Save $10,000+/year.
Step-by-step guide to access, pricing models, and cost optimization
Step-by-step guide to access, pricing models, and cost optimization
 How to Access GPU Cloud?
How to Access GPU Cloud?
Sign up (5-10 min). Enable GPU instances (verification needed).
NVIDIA V100/T4/A100 or AMD MI300X. See GPU comparison.
 IaaS, PaaS, SaaS for GPU Cloud
IaaS, PaaS, SaaS for GPU CloudFull control. Rent raw GPUs.
Example: Train AI model on 8x A100 GPUs.
No GPU management. Focus on code.
Example: Deploy AutoML pipelines without DevOps.
Ready-to-use AI apps. No infra knowledge needed.
Example: Detect objects in images via API call.
 Types of GPUs in the Cloud
Types of GPUs in the Cloud| GPU Model | FLOPS (TFLOPS) | Memory (GB) | Amazon | Azure | Google Cloud |
|---|---|---|---|---|---|
| NVIDIA V100 | 14 TFLOPS | 16 GB HBM2 | P3 (8xV100) | NCv2 | N/A |
| NVIDIA T4 | 8.1 TFLOPS | 16 GB GDDR6 | G4dn | (T4) | N1 (T4) |
| NVIDIA A100 | 312 TFLOPS | 40 GB HBM2e | P4 (8xA100) | NC A100 v4 | A3 (8xA100) |
| AMD MI300X | 163 TFLOPS | 128 GB HBM3 | Coming Soon | ND MI300 v5 | N/A |
| Google TPU v3 | 420 TFLOPS | 32 GB HBM | N/A | N/A | TPU v3 Pods |
Source: NVIDIA, Google Cloud TPU
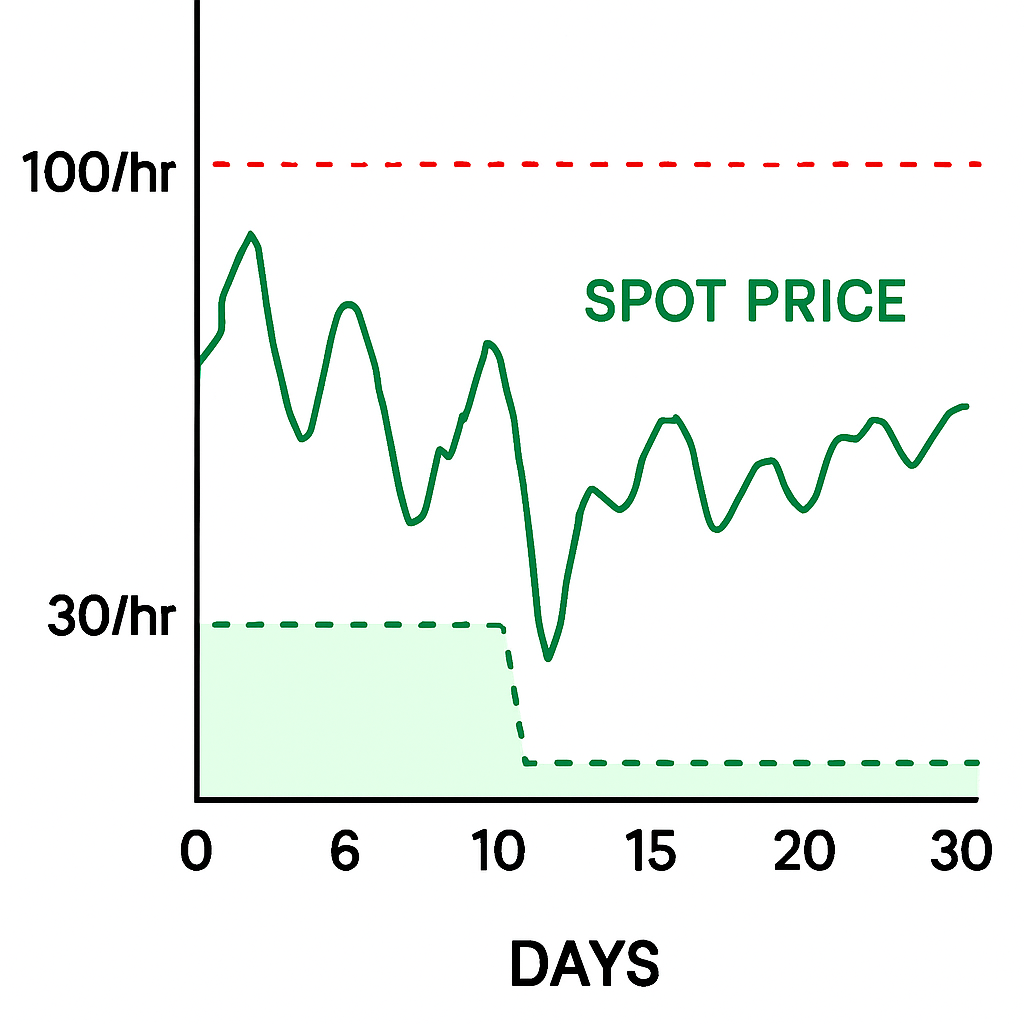 Cost Models: On-Demand vs Reserved
Cost Models: On-Demand vs ReservedPay per hour. No commitment.
Commit upfront. Up to 60% off.
Unused capacity. Up to 90% off.
Unlock the full power of accelerated computing and take your AI projects to the next level. Our experts can help you design, optimize, and scale your infrastructure.
Contact us & get started 🚀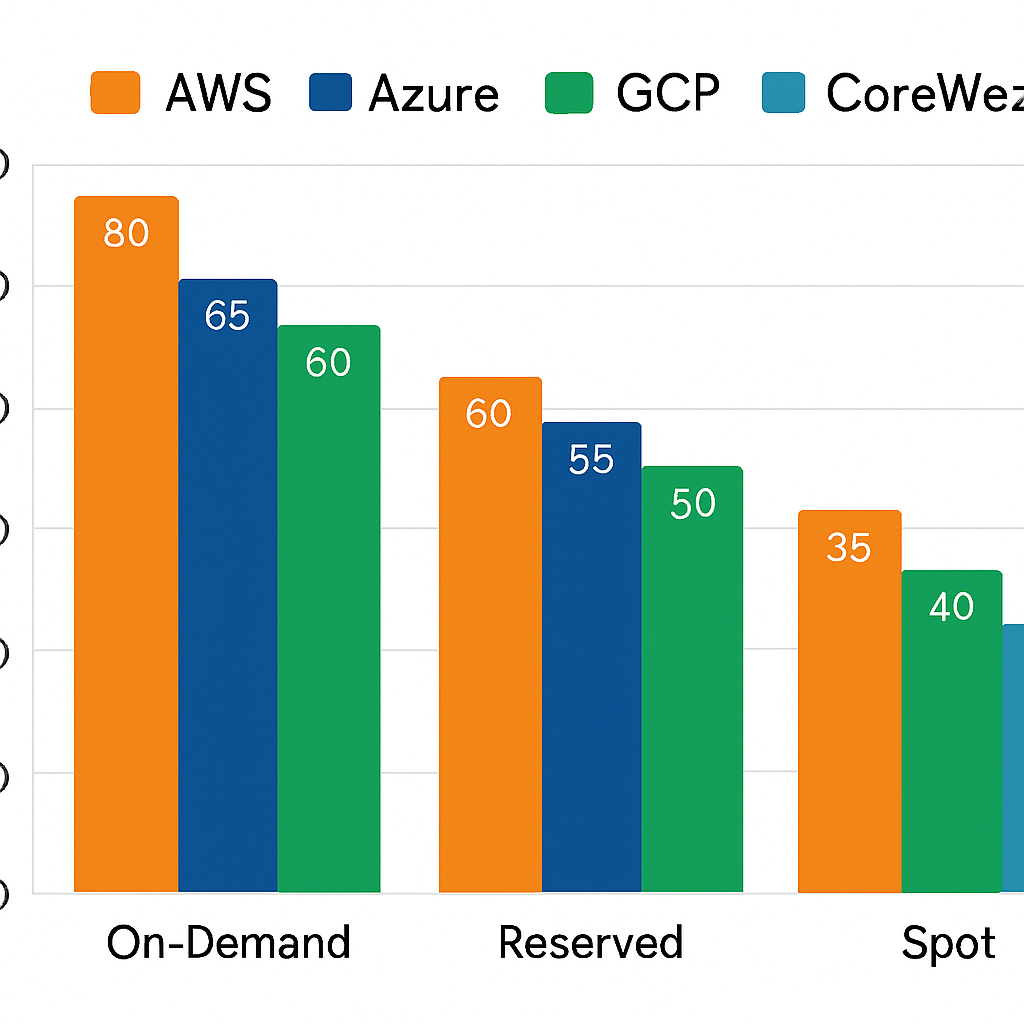 Source:
Source: